


2. Hands-On Teaching Digital Humanities: A Didactic Analysis of a Summer School Course on Digital Editing
Malte Rehbein and Christiane Fritze
This chapter discusses the rationale behind a week-long summer school course on digital editing in detail: its background, learning objectives, course content, methods, tools and media employed and the outcome of the course. It analyzes this approach by juxtaposing the course objectives with outcomes from a didactic perspective—that is, from the educational perspective of teaching the course. This chapter covers two areas of investigation: first, summer schools (or similar workshops and seminars en-bloc), as opposed to university teaching with face-to-face teaching every week, and second, digital editing through a holistic approach, rather than as a course focusing on particular aspects such as text encoding. The chapter is intended to present documentation as well as critical analysis that we hope will provide some guidance for similar enterprises.
Motivation
Summer schools and workshops are common formats of conveying skills in digital humanities because regular curricula on university level do not exist in any comprehensive way and due to the fact that such skills are becoming more and more relevant as part of members of faculty’s further training and for projects in the humanities.
In comparison to other aspects of digital humanities, digital editing appears to be a particularly collaborative and comprehensive process, requiring a wide range of skills. As Peter Shillingsburg has noted,
Creating an electronic edition is not a one-person operation; it requires skills rarely if ever found in any one person. Scholarly editors are first and foremost textual critics. They are also bibliographers and they know how to conduct literary and historical research. But they are usually not also librarians, typesetters, printers, publishers, book designers, programmers, web-masters, or systems analysts. In the days of print editions, some editors undertook some of those production roles, and in the computer age, some editors try to program and design interfaces.1
What Shillingsburg implies here is the need for specific training in this area—that the required skills need to be taught—and this has to be reflected in didactics: the required skills need to be taught. The complex nature of the underlying process of digital editing requires a comprehensive educational approach encompassing a broad range of learning objectives.
The idea of designing a course on digital editing following these considerations had a second motivation derived from our experience of teaching digital humanities topics in both summer schools/workshops and in university curricula. This experience led us to the experimental “learning-by-project” approach that we are going to discuss in this chapter.
Our experience persuaded us that the practices of text encoding and data modeling, in particular, could be frustrating for students. It was always difficult to explain the rationale for certain tasks (such as creating a metadata model or encoding texts) and to illustrate their place within scholarly activity. This is because these tasks can only be understood abstractly aside from their place in the production of a digital resource in general and a digital edition in particular. Single exercises accompanying each step of the whole process could not establish the necessary connection for understanding and left students dissatisfied with their grasp of the topic. Hence, we decided to offer a learning-by-project approach aiming at group work to devise a small-scale edition, with the support of an out-of-a-box digital editing system. Participants were encouraged to collaborate with each other and to contribute their particular competencies and interests. The driving philosophy was to get the students involved in the complete process of creating and publishing a digital edition, from the first encounter with the material to its web presentation. Through this holistic approach we hoped not only to convey a better understanding of the process but also to evoke an intrinsic motivation by completing a “real” (not only educational) project, to create something tangible and yet unpublished.
The innovation in this approach was two-fold: firstly, it did not focus on particular aspects of digital editing, such as TEI-based text encoding, but covered the complete life-cycle from planning the project to publishing. Secondly, we did not work with discrete exercises unrelated to the project but with one set of data that was enriched gradually during the course of the week—a format that would ideally serve as a model for a “real” project.
Background
ESU Summer school
The second Europäische Sommeruniversität “Kulturen & Technologien” or European Summer School on “Culture & Technology” (ESU) took place from July 26 to 30, 2010, at Leipzig University. It aimed to bring together postgraduates and early- career researchers in the arts, humanities, engineering, and computer sciences to foster cross-disciplinary networking and encourage future collaboration. The initiator of the ESU, Elisabeth Burr, describes its ongoing mission as
Seek[ing] to offer a space for the discussion and acquisition of new knowledge, skills and competences in those computer technologies which play a central role in Humanities Computing and which increasingly determine […] the work done in the Humanities and Cultural Sciences, as well as in Libraries and Archives everywhere.2
The week-long schedule of the Summer School was dominated by parallel workshops with a maximum of 20 participants each. The workshops were accompanied by plenary presentations of selected participants’ projects in the afternoons as well as invited lectures by digital humanities specialists in the evenings. Each workshop comprised 15 sessions of 90 minutes, hence three sessions each day, and was led by two international instructors. The workshop From Document Engineering to Scholarly Web Projects looked behind the scenes of scholarly web publishing. Digital History and Culture: Methods, Sources and Future Looks stressed digital methods, tools and theory of online history projects. Methods in Computer-Assisted Textual Analysis dealt with the basic corpus linguistic methods using statistical software. This chapter treats the outcomes of the workshop taught by the authors on Introduction into the Creation of a Digital Edition.
Participants
The Summer school was designed for an international clientele. The majority of the participants came from Central and Western Europe, but graduates and young researchers from Eastern Europe, India, Sri Lanka, and Brazil also attended the Summer University. The prospective candidates had to apply for participation and specify one workshop; the course instructors reviewed their applications.
Our class was finally attended by ten participants from Germany, Poland, France, Italy, Canada, the USA and China.3 The cultural background of the participants differed significantly and so too did their level of graduation. About half of them were still graduate students whereas the other half comprised of young and advanced researchers in the humanities.
Disciplinary backgrounds were heterogeneous as expected but, in principle, all of the students came from the cognate fields of philology, language and literature studies. Of course, the languages and major areas of interest differed: 60% of the students planned to start editorial work, focusing for instance on fifteenth century manuscripts or on indigenous and mestizo chroniclers in colonial Mexico or on a Russian émigré’s journal; 40% of the participants had in mind a linguistic analysis of the edited texts later on. The level of familiarity with the process of editing, on the one hand, and the use of digital humanities methods, on the other, showed a similarly wide range. The average age of the participants was 29 years, ranging from 23 to 40 years old; 70% were female, 30% male.
Overall, we expected student characteristics to vary in terms of prior knowledge, intellectual abilities and epistemological level. We also expected different learning styles and anticipated catering for these by a blend of learning methods. Our general assumption was that of a heterogeneous group of students with backgrounds in different fields in the Humanities but new or fairly new to digital humanities.
The Course on Digital Editing
Course Objectives
The course was announced on the ESU website as an introduction to the “techniques and methods of a digital editing project … designed as an interactive experiment in which we work on a small corpus of manuscripts and bring it to online publication.” The announcement noted the course’s “learning-by-doing approach,” in which the “typical processes in the creation of a digital edition are experienced by the participants” that are expected “to collaborate which each other during the workshop and to bring in their particular competencies and interests.” The topics to be covered in the course included conceptualizing the editorial project; document analysis; data modeling; transcription, annotation and encoding; quality assurance; transforming and visualizing textual data; and online publication.4 The main emphasis of the course was to be determined in consultation with the participants, with material provided by the instructors. The practical part of the workshop was estimated at 75% of the total time.
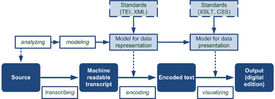
For the purposes of the workshop, a “digital edition” was understood as a scholarly edition not only created with the support of digital methods and tools but also one to be distributed by digital media—in this case, the internet.5 The learning objectives of the workshop were shaped around this definition. Students would learn about the process of digital editing as a whole or, more generally speaking, about the application of digital methods for creating online resources. For this, we chose as a basis the reference model illustrated in Figure 1 and discussed in greater detail below. The workshop also had a second-order objective that was actually to create such a resource or edition and prepare it for publication as far as possible, i.e. to finish a small-scale project.
Scholarly editing in general, comprising textual criticism, however, was not the primary concern of the workshop. However, we did consider the variety of the group’s prior knowledge, especially regarding philology, and included a very basic introduction into the main principles of scholarly editing.6
The workshop also served as a test-run for our claim to combine learning objectives with project-like objectives. We expected this goal to be very demanding but wanted to see what progress we could make. The didactic, that is, educational objectives had priority, however. The experimental character of the workshop was not a hidden agenda. It was announced in the workshop description and clearly communicated to the participants in advance.
Learning Goals
In preparation for the workshop, we defined the following learning goals (Table 1).
Most of these learning goals focus on knowledge and cognition. However, the last (but not least) objective—to experience collaborative work—has also a strong affective aspect, especially taking into account the heterogeneity of the group and the fact that members did not know each other beforehand. We stressed collaborative work by making it a learning goal, as traditional work in the humanities (too) often appears as a solitary enterprise while digital humanities projects are often conducted in groups.7
Learning Outcome |
|
1 |
To understand chances and challenges of the digital medium for scholarly editing. |
2 |
To understand digital editing as a holistic process and to know typical phases in a digital editing project, methods and technologies applied and standards used in each phase. |
3 |
To know typical infrastructural requirements for a digital editing project and to use such an infrastructure. |
4 |
To know the definition and purpose of data modeling, to understand its importance in a project and to apply modeling techniques in simple editorial projects. |
5 |
To apply the Guidelines of the Text Encoding Initiative (TEI) to encode “easy” texts and to use the Guidelines for further self-study |
6 |
To be able to apply Cascading Style Sheets (CSS) for simple data representation. |
7 |
To experience collaborative work. |
Table 1. Learning goals.
Course Set-Up
This section deals with the didactic principles and the overall planning of the course. The section following analyzes the “performance” that actually took place in the classroom.
Content: Developing the content of the course was based on the two prevailing conditions: first, to cover the editorial process as a whole, beginning with the selection of the material and ending only with the publication on the internet, and second, rather than using separate exercises, for the single parts to employ one object of study and process it through the various stages of what we regarded as a typical workflow. This required that the results of one phase should influence the course as a whole, by becoming the input for the next phase. For instance, the agreement on a model for encoding textual features needs to be observed in the actual encoding; the definition of metadata made within the course provides the basis for the customization of the database etc.
As a model for the project workflow, we followed the digitization process used by the Brown University Women Writers Project or WWP (http://www.wwp.brown.edu/), in many ways typical of XML-based digital humanities projects, and modified it to suit the particular needs and scope of the workshop (Figure 2).
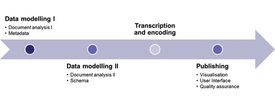
Figure 2. Reference process for digital editing.
Data Modeling: This is understood as the core process aimed at creating digital resources, such as an edition.8 In our model workflow, data modeling occurs in two phases:9 one models the representation10 of the source data as input (in this case, texts and images of the documents) into the digital medium (i.e. it describes the “real world”), and the other models the presentation of the data as output (Learning Goal 4).11 Here we follow Willard McCarty’s definition:
By “modeling” I mean the heuristic process of constructing and manipulating models; a “model” I take to be either a representation of something for purposes of study, or a design for realizing something new.12
Modeling the representation of data means analyzing the material with the project’s objectives and deriving from both—by applying modeling techniques such as abstraction and generalization—the rules for transforming the material into the digital medium. This includes its metadata, to cover the corpus of letters and to allow for database integration, as well as defining rules for text encoding.
In data modeling, a two-step approach suggested by Alexander Mehler and others was envisaged.13 Beginning with the analysis of the material and the requirements, we would develop a conceptual model (expressed in natural language) and derive from this a formalized (logical) model (expressed in a formal language). We decided on entity-relationship models for metadata and XML-schema for textual data.14
Transcription and Encoding: In the context of this course, we understand transcription as the process of transforming the texts carried in the letters as physical objects into machine-readable format, basically as a sequence of characters. Encoding is the next step of enriching this (raw) data into processable information by making explicit structural and semantic features.15 We chose to use the P5 Guidelines of the Text Encoding Initiative as the basis for both encoding metadata and text,16 and to enable us to teach their basics (Learning Goal 5).
Publishing: This encompasses the design of the to-be-created digital edition in terms of data presentation or visualization (Learning Goal 6) and the interaction between the user and the data by means of a user interface (human-computer interaction). We used the WWP as a reference and, following its strong emphasis on quality assurance in the model, we took this also as part of the publishing workflow.
Modeling the presentation of the data necessitates analyzing (or reconsidering) the models developed for data representation as well as the project’s objectives in order to identify the design of the online resource, i.e. to create a blueprint for the digital edition. The purpose of a digital edition consists in the interplay of these two models: “modeling of something readily turns into modeling for better or more detailed knowledge of it.”17 These considerations led us to emphasize data modeling strongly in this course.
Digital Editing Infrastructure: This infrastructure is meant to support the whole workflow as much as possible. This includes the production of the digital edition as well as serving as the “host” for its publication. The role such infrastructure plays in both the production and publication process must be taught (Learning Goal 3).
The outline of the course contents helped us to sharpen learning goals so that in addition to the main objectives (as described in the previous section) some second-order goals (documented in Table 2) could be achieved.
Goal |
Learning Outcome |
8 |
To gain insight into the different approaches of digital editing, to know selected sample projects and to assess them in terms of claim, audience, functionality, methods of data representation, data presentation and human-computer interaction. |
9 |
To know selected tools supporting the various phases in digital editing. |
10 |
To know some of the major principles as well as basic techniques of data modeling. |
11 |
To learn fundamentals of Entity-Relationship modeling and to be capable of applying this method to an easy example. |
12 |
To understand transcription as part of a digitization process and to know different approaches and their advantages and disadvantages. |
13 |
To understand XML as a means for data representation and XSLT as a means for data presentation. |
14 |
To know and be able to apply the principles and basic rules of XML; |
15 |
To learn the main principles of the TEI and to gain insight into selected chapters of the TEI guidelines. |
16 |
To become aware of the necessity to agree on and use standards. |
17 |
To understand the necessity of quality assurance in a scholarly project. |
Table 2. Second-order learning goals.
To provide the students with an appropriate background, we decided to teach the additional theoretical lessons as documented in Table 3.
Lesson |
Description |
1 |
History and types of (scholarly) editions since the eighteenth century. |
2 |
Examples of digital editions: the German Text Archive (http://www.deutschestextarchiv.de/), the kundige bok digital edition (http://kundigebok.stadtarchiv.goettingen.de/), the Thomas MacGreevy Archive (http://www.macgreevy.org/), and the Diary of Robert Graves 1935-39 (http://graves.uvic.ca/graves/). |
3 |
Digital editions based on the SADE-infrastructure. |
4 |
Modeling in general (following Stachowiak 1973) and its principles (such as classification, structuring, abstraction), modeling as a process, and entity-relationship modeling as an example (Chen 1976). |
5 |
Basic principles and rules of XML. |
6 |
Functionality of oXygen XML editor as an example of specialized XML editing software. |
7 |
History and scope of the Text Encoding Initiative, and essential rules of the TEI Guidelines. |
8 |
Schema, ODD, and ROMA. |
9 |
Metadata according to TEI (teiHeader). |
10 |
Pros and cons of different transcription approaches (e.g. OCR, double-keying). |
11 |
|
12 |
Theory of information visualization and its role in digital editing. |
13 |
Examples of visualizing textual data: the Republic of Letters project (http://toolingup.stanford.edu/rplviz/), Wendel Piez’s Overlapping project (http://www.piez.org/wendell/dh2010/clix-sonnets/), and Ben Fry’s Preservation of Favoured Traces visualization of Darwin’s On the Origin of Species (http://www.benfry.com/traces/). |
Table 3. Additional theoretical lessons.
All these considerations led to the outline of the course as shown in Table 4. Each module was initially assigned a session of 90 minutes. We started with some “team building” to get to know each other and to learn more about the cultural and disciplinary background of the participants and then introduced the course design and the material. Most of the time in the workshop was spent with a series of theoretical, methodological and practical sessions that went step-by-step through the intended digital editorial process. The workshop concluded with project consultations and a course evaluation.
Module |
Title |
Learning Goal |
Content |
M1 |
Introduction |
|
Course objectives and outline (T) |
M2 |
Digital Editing |
|
Exemplary overview of printed and digital editions Discussing the project’s (Ehrlich letters) objectives (P) |
M3 |
Digital Editing Infrastructure I |
3 |
The SADE infrastructure I (T) |
M4 |
Data Modeling I |
4 |
Theory of data modeling I (T) |
M5 |
Text Encoding I |
5 |
XML Basics (T) |
M6 |
Data Modeling II |
4 |
Document analysis III: text (P) |
M7 |
Text Encoding II |
5 |
TEI Basics II (T) |
Text Encoding III |
5 |
TEI Basics III (T) |
|
M9 |
Text Encoding IV |
5, 7 |
Transcribing and encoding (P) |
M10 |
Digital Editing Infrastructure II |
3 |
The SADE infrastructure II (T) |
M11 |
Visualization |
6 |
Theory of information visualization (T) |
M12 |
User Interface |
3 |
Implementation of functionality into SADE (T/P) |
M13 |
Quality Assurance |
7 |
Quality assurance (P) |
M14 |
Wrap-Up |
|
Recommendations for further reading and practice (T) |
M15 |
Project consultation |
|
Project consultation (P) |
Table 4. Course set-up details, indicating theory (T) and practical (P) sessions.
The Object of Study
Keeping these comprehensive learning goals in mind, careful consideration was required in order to find the appropriate materials to build the workshop. The following criteria, derived from the learning goals and the given constraints (number of participants, language, diverse backgrounds, prior knowledge and time for the workshop), guided our search:
- The materials should not be too comprehensive so as not to discourage the students with unrealistic goals.
- The corpus needed to be dividable into smaller portions, ideally equal in length and difficulty, so that students could work on their own portion of the whole corpus.
- The complexity of the source material in terms of textual features and the length of texts should be moderate; not too simple but not exaggerated.
- As we were not teaching paleography, we also had to ensure that the sources could be transcribed without special skills.
- The material should be comprehensible by all students; as the teaching language was English, English texts were preferred.
- Ideally, the material should not have been published yet as we hoped to increase students’ motivation by doing something new.
- Copyright issues should not play a role.
Finally, thanks to the support of the special collections of the Universitätsbibliothek Würzburg, we came across a small corpus of letters from Paul Ehrlich that we found appropriate. These letters fulfill most of our criteria: the level of complexity of the letter-genre can be scaled according to the learning goals and the length of the single texts is moderate in such a way that each student or a small group can work on a clear-cut resource that still has a connection to the work of the other students. In the international context of the summer school, there is a drawback, however, as the language of that material is German.
The chosen collection (UB Würzburg, Paul Ehrlich Nachlass/1) consists of twenty typewritten and two handwritten letters with a length between one and six pages. The typewritten letters (see Figure 3 for an example) show some handwritten corrections and additional notes by their author, Paul Ehrlich. Other noticeable characteristics are the well-set letterheads and opener lines, attachments, colored passages, page numbers and marginal notes.
Paul Ehrlich (1854–1915) was a highly celebrated German scientist who conducted research in the fields of immunology and serology from the late 1870s until his death in 1915. In 1908 he became a Nobel Prize laureate in Medicine together with Ilya I. Mechnikov. All letters of the collection in question are addressed to Bodo Spiethoff. Spiethoff studied medicine in Berlin and Jena and, during the time of this correspondence, was an associate professor at the Universität Jena and practitioner in dermatology.
This correspondence between Ehrlich and Spiethoff took place between 28 June 1910 and 30 April 1914. The discussion between the two scientists was mainly about the further testing of the first effective chemotherapeutical remedy, the Salvarsan-Kur (the so-called “606” or Arsphenamine treatment) against syphilis.18 Unfortunately, only the letters from Ehrlich to Spiethoff are extant, at least in this collection; the content of Spiethoff’s letters to Ehrlich can only be projected. In view of the educational objectives of the course, this is a negligible drawback. For publication and future research of this material, however, and discussion between the two scientists in the field of history of medicine, it remains a desideratum.

Figure 3. Sample letter (Paul Ehrlich to Bodo Spiethoff, dated December 15, 1910) from the Paul Ehrlich Nachlass (UB Würzburg Nachlass Ehrlich 1,1,15). Reproduced by kind permission of Universitätsbibliothek Würzburg.
Didactics: Teaching Strategy and Methods
In order to find the best teaching methodology to bring this enterprise to a success, it soon became clear that we needed, first, a blend of didactic methods to cater for the heterogeneity of the group as well as for the wide range of learning objectives, and second, that each session should consist of both a theoretical and a practical part.
We intended the theoretical part of each session mainly to comprise lecturing—the “traditionally favored university teaching method”19—instructive discourses, demos and other (visual) presentations by the instructors. The practical parts of the workshops would allow sufficient student participation and interaction to apply the techniques learned beforehand and to use the tools that were introduced by the instructors, whose role was then that of tutors, moderators, and coaches. With regard to the the overall ratio of theoretical and practical parts, or from the students’ perspective, passive and active participation, it was envisaged that 75% of the time allocated for the workshop would be spent on practical work.
All chosen methods address the cognitive domain of learning. Following the categorization by Diana Laurillard,20 our teaching strategy encompasses all four main domains: discursive, adaptive, interactive and reflective. It is discursive as the establishment of a “discussion environment” is a key aspect of the theoretical parts; adaptive by the interplay of theory and practicing; particularly interactive as “students must act to achieve the task goal”; and reflective, i.e. as the students “must reflect on the task goal, their action on it, and the feedback they received” with the latter two domains being covered by the practical parts of the course.21
Building upon this more general discussion of teaching strategy, we decided on the best methods for achieving the six major course objectives in conjunction with the content we wanted to convey. One in particular had to be taken into consideration: we intended to use the results of one phase of the course—data models developed by the students provided input for the next phase—and so not only did course content need to be carefully coordinated but we needed to determine a corresponding blend of didactic methods (Table 5).22
Table 5: Teaching methods employed for practical sessions.
Tools and Media
The course was to be taught via local facilities: in a computer lab of the Faculty of Philology of the Universität Leipzig, which is equipped with a data projector, white board and flipchart. In preparation of the course we set up a wiki using MediaWiki (http://www.mediawiki.org/) and later encouraged the students to document the results of discussions and the joint development of concepts within this wiki (see Figure 7). In addition, the Summer school provided the e-learning platform Moodle (http://www.moodle.org/) to manage the exchange of instructors’ slides across all four workshops. This system was also intended to manage feedback to the Summer University as a whole and as a means to stay in contact.
Again, referring to Laurillard and her categorization of “media for learning and teaching,”23 we came up with a blend of tools and media to cover all areas she suggests. We intended to employ narrative media for presentations; interactive media for demonstrations; and communicative media for discussions and documentation. The technical infrastructure we provided and used is an adaptive medium in the sense that it served the application of theoretical knowledge to practice and it is a productive medium as it also formed the platform the to-be-developed digital edition. This is discussed in greater detail in the following section.
Technical Infrastructure
As mentioned earlier, one of the learning objectives was to teach the requirements for and the usage of infrastructure for digital editions. For the practical aspect of the course, we needed such technical infrastructure not only for publication (as a productive medium) but also to support the whole process as much as possible (as an adaptive medium). The system we were looking for should be easy to install, easy to use and its different components should be well coordinated so that the technical setup could be regarded as a black box instead of dealing with loosely coupled single components.
Key requirements from the production perspective are:
- Easy access to the infrastructure from the lab’s computers and participants’ laptops;
- Capacity for collaborative and synchronous work on the same project;
- Support for the creation of relevant models for metadata, text representation and visualization; and
- Transcription and encoding of texts.
Key requirements from the publication perspective are:
- To grant (online) access to the edition;
- To bridge automatically between data representation and data presentation, i.e. the facility to apply stylesheets to encoded texts and to display images; and
- To support basic browse and search functionality.
From a didactic perspective, another requirement arises:
- The impact that certain actions in the editorial process (e.g. changing metadata or encoding textual features) have on the final product should be conceived by the students immediately, i.e. made visible and transparent.
We finally decided to use the Scalable Architecture for Digital Editions or SADE (http://www.bbaw.de/telota/projekte/digitale-editionen/sade/) system developed by Alexander Czmiel (Figure 4).24 As SADE is a prebuilt framework containing substantial components for both creating and publishing a digital edition, it seemed a suitable instrument for our purposes as it provides:
- A native XML database to store the encoded documents;
- A web publishing framework;
- TEI-aware default transformation stylesheets;
- A customizable search interface; and
- An image viewer.
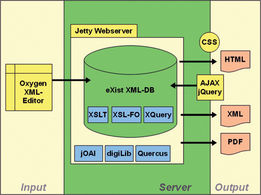
Figure 4. Components of the Scalable Architecture for Digital Editions (SADE) framework. Image sourced from the SADE project documentation.
The SADE framework addresses small-scale editions hence, the Ehrlich letter corpus fitted well into the system in terms of size. SADE is a bundle of software based on open standards. The main elements of SADE are a Jetty Webserver, which contains the native XML database eXist (http://exist.sourceforge.net/) and the digilib image server (http://digilib.berlios.de/). The database contains several TEI-aware XSLT stylesheets as default which transform TEI-conformant XML documents into a HTML presentation within the digital edition website or a PDF to download. All TEI stylesheets are SADE customizations based on the stylesheets developed and maintained by the TEI Consortium.
This scalability of SADE can be understood in both directions. On the one hand, the editor is free to develop XML documents fulfilling the demands of each specific edition. On the other hand, the user has the possibility to generate transformation scenarios and to fulfill specific layout requirements. The second major component of our infrastructure, the XML editor oXygen (http://www.oxygenxml.com/), was used for transcribing, encoding and CSS/XSLT modification. It provides a webDAV interface that we wanted to use for integration into the overall framework. Once connected with the eXist database of the SADE framework, it allows the students to work on the same data at the same time. For this purpose, the SADE framework was installed on a server (kindly provided by the Centre for Digital Editions at the Universität Würzburg) and made publically accessible. All desktop computers of the lab were equipped with the XML editor, which is a desktop- (and not a server-) based application, by the local assistants in advance. Nonetheless, the participants worked mainly on their own laptops.
For the generation and customization of our formalized data models (for metadata and text encoding) in the form of XML schemata, ROMA (http://www.tei-c.org/Roma/) appeared to be appropriate. The combination of components outlined here, with the SADE framework in its core, follows directly the principles of our model process for digital editing.
The technical infrastructure needed to be set up in advance, of course, so that it ran smoothly during the course. This included the preparation of source material, i.e. its image digitization and a preliminary OCR transcription to save time in the classroom.25
Course Performance
While the previous sections dealt with the intention, planning and preparation of the course, we now turn to assess the practical outcomes and performance of the course. To do so, we highlight relevant modules from the overall course set-up (cf. Table 5) and focus on the practical parts that required students’ interaction. This is done through the different didactic methods employed (Table 2). Overall, we can confirm the initial intention of spending 75% of the course on hands-on practice rather than on conveying theory.
Introduction
As planned, we started with “warm-up exercises” not only to get to know each other and to create a comfortable learning atmosphere but also to learn more about the technical skills of our students. Some icebreakers during the introductory session served this purpose well. In this way, we had a grasp of their prior knowledge, familiarity with the theme of the course and their literacy with regard to computer technology.
In the introductory session, we also decided to build small teams of two students each to perform the practical tasks together, especially transcribing and encoding. This had a pragmatic rationale: four of the ten participants were native German speakers and as the language of our material was German, we could fill most teams with one German and one non-German to overcome language limitations.
Data Modeling
The most interesting sessions, with respect to didactics and in the context of the overall objective of bringing the material into a publishable form, were arguably those that encompassed data modeling—be it for modeling the requirements of the final product, metadata, text or visualization. In all modeling sessions, we built teams of three or four students, gave each team the same instructions, taken from our model editorial process, and let them work in teams for a certain amount of time (usually approx. 30 minutes). Each team was then asked to present their results, which were later documented on the wiki, and to discuss them with the whole group. The final discussion led to an agreement on one of the proposed (mutatis mutandis) models. To illustrate this approach, the instructions for one of the modeling sessions (modeling text, M6) were as follows:
I. |
Conceptual model |
|
|
a. |
Look at your document(s) and browse through the other material: What could be marked up? |
|
b. |
Now consider the project’s objectives (purpose of modeling): What needs to be marked up? |
II. |
Formal model |
|
|
a. |
So far, we know what to encode, but only in a conceptual view. Now, design a TEI schema to formalize this and to prescribe in a formal way, how to encode. |
Figure 5 illustrates the outcome of two modeling sessions: on the left, entity-relationship models developed by the students for metadata (formal model) and, on the right, the documentation of the model for encoding text (conceptual model). The following gives a brief overview of the achievements during the various analyzing and modeling sessions.
Objectives of the digital edition: These encompassed what the to-be-developed final product would feature. After creating an initial collection, the students were asked to prioritize these features (high, medium, low, nice to have) and eventually an agreement was found. The key aspects are to grant access to all letters as images and as transcribed and annotated texts; to allow full text search; to allow browsing by recipient, sender, date and address; and to provide an index of medical terms.
Metadata: All models proposed were sound in their intellectual content; their formalization in an ER-model understandable and useful for the following discussions. An agreement on a model (entities, attributes and relations) was reached within reasonable time (Figure 5).
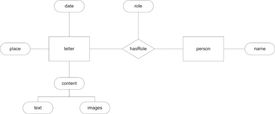
Figure 5. Metadata model developed during the course (entity-relationship notation).
Discussions on how to encode the metadata took place within the group after a theoretical introduction into teiHeader but—due to time constraints—finally predetermined by the instructors.
Text: The agreement on the model (and hence the encoding rules) was based on the synopsis of the results presented by the teams. One should note that this analysis was performed after a basic introduction into TEI but before explaining chapters of the TEI guidelines in detail, let alone introducing particular elements. Features to be encoded were: page and line breaks; text structure (paragraphs and lists); letter heads; address lines; greetings, signatures, openers and closures, occurrences of person names, place names, dates, numbers and technical terms; features of textual corrections (deletions, additions, substitutions).
Transcription and Encoding
Since we had ten students in the class and paired them up for the practical work, only five letters could be transcribed and encoded. Therefore, it soon became clear that we needed to abandon the idea of bringing an edition of the whole corpus into publishable format. instead, we concentrated on a selection of letters.26
Transcribing the letters from the digital surrogate of their (typewritten) original was partly supported by OCR-software. This was primarily done to introduce the students to the different ways of transcribing (automated, keying) and secondly not to waste time in the classroom by repetitive tasks. However, the quality of the results from the OCR process was poor and often required manual intervention. A more careful preparation might have overcome this issue.
Encoding the letters raised—apart from the language constraints of the non-native German participants—anticipated problems in encoding lessons as well as in encoding projects. They encompass two areas: first, the question of how to decide on a certain feature of the text e.g. is “water” a medical term or not, and second, how to encode features not covered in the theoretical introduction. These challenges cost more time than expected and regularly needed to be discussed in the plenum. Overall, we have achieved less than we hoped in transcribing and encoding the letters.
Publishing
Although we intended to pay high attention to quality assurance and devoted a whole session to at least crosscheck the work, the students mostly neglected it. An evaluation of the encoded texts after the completion of course hence revealed many flaws.
With regard to visualization, the students experimented a little bit with CSS and their impact on the display of the texts, for which the SADE infrastructure provided an intuitive tool. The visualization of textual features remained incomplete, however, and the layout of the digital edition as a whole rudimentary (Figure 6).
Figure 6. Screenshot of the edition at the end of the course.
The functionality for the edition was provided by the SADE infrastructure and customized by the instructors. As the course was dynamic in the sense that the results from one phase built the basis for the next phase of editorial work, it required nightly work by the instructors in order to prepare the system for the next day, e.g. to write XQuery scripts (required for database integration) to handle metadata in the format defined by the group during the day or to adopt stylesheets according to the encoding rules the group had agreed upon.
Regarding the infrastructure, we achieved our aims. The course appeared as collaborative work and the students could immediately follow the work of their peers. Even in the early stages of the project, one could grasp the edition holistically and see it growing and improving (new documents uploaded, encodings corrected, style sheets enhanced, etc) step-by-step.
Different style sheets were developed and uploaded and allowed the students to experience the relation between representation and presentation of data. Visualization of basic textual features, such as substitutions or highlighting of names, was accomplished. At the end of the Summer school, our edition allowed one to browse the corpus by date, place, sender and recipient.27 A full-text search and an alphabetic index of medical terms were automatically created and linked the entries to their occurrences in the text as well as to Wikipedia.
However, it took a lot of time to get the system running. Setting up database connections (in oXygen), granting access and providing passwords may have been better prepared by the instructors. But it is generally a task that is time-consuming and risky in a classroom with a heterogeneous audience where one has to deal with different levels of computer literacy, various operating systems and so on.
Figure 7. Sample screenshot from the wiki made during the course, documenting the discussions on data models.
Evaluation
In this final section we draw to a conclusion by critically assessing and didactically analyzing this summer school course. We do so by first looking at the feedback the students gave to us after the course, second by drawing our own lessons learned by evaluating course performance versus course objectives and third, we provide a possible explanation of mismatches.
Participants’ Feedback
At the end of this summer school, we asked the participants to give us their feedback on the course. This was collected in form of an open discussion, occasionally intervening by asking questions or insisting on issues that were of particular interest for the instructors.
In general, the combination of theory and practical experience was considered positive. Many students stated that the theory (especially of data modeling and text encoding) was difficult to understand at first, but became clear while practicing. This might be assessed as positive feedback with regard to the didactic success. From our point of view, it is natural (and has to do with different learning styles) that some students preferred more practical work and regard the theoretical parts—from their perspective—as too abstract, while others stated the opposite. On average, the ratio between conveying theory and practicing it was regarded as well balanced.
Simply including practical exercises was not the innovation of our teaching approach. Working continuously on the same object throughout a complete value chain in which the material was gradually enriched until it has reached its final output in a (more or less) nicely visible form (“actually seeing something on screen as part of a bigger story and not only markup”), accessible, searchable and browse-able, was regarded as rewarding and motivating. Another motivation was drawn from the collaborative approach in which all participants (or pairs) worked on the same material but had different tasks within the project, in our case by being responsible for different letters of the corpus.
While the theory we tried to convey in the lectures was generally assessed as being “too much” (and particularly as having “too much vocabulary”), the practical parts seemed to work well for most participants. The genre of letters and the corpus that we had chosen for this was regarded as appropriate. The shortness of the texts as well as the number of textual features to encode within the letters was appreciated: too few of them would not have allowed sufficient encoding practice; too many or too complicated features, however, would have led to frustration. It was also seen as useful that the corpus had texts of similar kinds so that the participants could help each other better. The students suggested working with texts in the English language, however.28
Regarding the digital editing infrastructure, the students grasped its role in the context of both creating and publishing a digital edition but their different components, let alone computational details, were considered too complex and, on a technical level, beyond the scope of this course.
It was commonly acknowledged by the participants that attending one summer school course can arguably only provide an outline of what digital editing involves and serves as a starting-point for further self-directed studies or learning-by-doing.29
Lessons Learned
Changing the viewpoint to that of the instructors, we would like to discuss the achievement of the course (its “performance”) in comparison with the learning objectives.
In general, what is realistically achievable in such a course? In particular, what is the best the balance between broadness (covering the whole editorial process) and depth (e.g. detailed knowledge of certain aspects)? It became clear that one cannot equally serve both objectives—the generalist as well as the specialist—in such a short time. In retrospect, the course achieved a generalist overview. For example, teaching the basic rules of entity-relationship modeling and using them in this phase of the project (modeling metadata) was useful as a means to make explicit what would otherwise be neglected. In this course, however, entity-relationship modeling was used more as a tool to force the students to think systematically and describe the object of their study rather than claiming that entity-relationship modeling is necessary in any digital editing project and aiming to enable the students to use this technique perfectly.
To what extent is the course a starting point for the participants’ own work? Although this had not been explicitly declared as a learning objective, it became clear in retrospect that it should be the overall objective or aim of the course. The students’ feedback confirmed that the course enabled them to do further work and self-directed studies particularly through its generalist approach. Teaching students to use the TEI guidelines seems to serve this purpose better than thoroughly discussing single elements.
From these more general considerations, we would like to assess the achievement of the six major learning objectives as outlined in Table 1, compared with the actual course performance (Table 6).
Learning Goal |
Projected Learning Outcome |
Actual Course Performance |
1 |
To understand chances and challenges of the digital medium for scholarly editing. |
Although difficult to assess, we believe that this objective could be achieved. What appeared to be really helpful was the fact that the course was embedded into the program of the summer university which allowed the students to learn about many other applications of the digital medium for the humanities. |
2 |
To understand digital editing as a holistic process and to know typical phases in a digital editing project, methods and technologies applied and standards used in each phase. |
This was certainly the main outcome and benefit of the course, although “know” could only be achieved on a generalist perspective (see above). |
3 |
To know typical infrastructural requirements for a digital editing project and to use such an infrastructure. |
This was part (and a requirement) of the “holistic process” of learning goal 2 and as such conveyed at least superficially. Deeper knowledge and understanding could not be conveyed (see above). |
To know the definition and purpose of data modeling, to understand its importance in a project and to apply modeling techniques in simple editorial projects. |
Although this was one of our focuses for the course, especially the last aspect of this objective—to apply modeling techniques—must be regarded as too ambitious. For the other two aspects (knowing and understanding), the same assessments apply as for learning goals 2 and 3. |
|
5 |
To apply the Guidelines of the Text Encoding Initiative (TEI) to encode “easy” texts and to use the Guidelines for further self-study |
This objective could be fully achieved. But naturally, in comparison with a weeklong course on text encoding only, the wording “easy texts” needs to be taken literally. |
6 |
To be able to apply Cascading Style Sheets (CSS) for simple data representation. |
Here, we intentionally achieved less than in learning goal 5 as the theoretical introduction into CSS was not systematic. A stronger emphasis on this aspect might be advisable for the future. |
7 |
To experience collaborative work. |
Although the wording of this objective does not really allow measuring its achievements, collaborative work was certainly facilitated during the course. |
Table 6. Achievement of (major) learning goals.
Our non-didactic objective to “bring [the edition of the corpus] to online publication” was clearly too ambitious. The result of one week’s work was (naturally) quite far away from being publishable in both completeness and quality. What worked very well, however, was the succession of the various phases of our editorial process. Overall, our “final product” followed indeed the objectives the group had set in the beginning of the course, texts were encoded on the basis of rules defined by the group in the data modeling sessions, and the edition featured what was intended (browsing, etc).30
In the following, we would like to list some of the issues we encountered and suggest possible solutions that might help to prepare similar courses:
- With respect to organization, such a course requires extremely careful, anticipative and thorough preparation. In comparison to a “traditional” workshop with lectures and loosely (if at all) coupled exercises, the preparatory effort is higher and technical set-up takes longer.
- The “dynamics” of such an approach in combination with the heterogeneity of the group clearly requires two instructors respectively, one instructor and one tutor. In sessions in which the students are asked to reproduce something (e.g. set-up of a database connection) it is more helpful if one of the instructors explains and demonstrates while the other serves as a tutor and checks that everybody reaches the same level.
- The practical sessions require intensive coaching by the instructors.
- Concerning practicalities, minor details need to be taken into account or at least one should not be surprised. For example, oXygen installations can have different languages in the user interfaces. This makes explaining its usage a bit annoying; not everyone might be familiar with Moodle or a wiki or other tools you use, so introducing these tools takes additional time. The use of fewer systems than we did might be good general advice.
- It was very helpful that the SADE infrastructure we used covered most of our needs. This gave us the time to concentrate on digital editing as process performed as a humanist scholar rather than as “typesetters, printers, publishers, book designers, programmers, web-masters, or systems analysts,” to reprise (and for the future hopefully refute) Shillingsburg’s statement from the introduction of this chapter.
Some Concluding Didactic Considerations
As we have already said, one of the main benefits of the course was a general overview of what is involved in digital editing and the basic principles of editing workflow and infrastructure. The learning objectives, however, were too ambitious and hence feedback like “too much” or “too much vocabulary” should be taken seriously.
Reviewing for a final time our learning objectives and regarding them in the light of the learning taxonomy suggested by Benjamin Bloom and revised by Lorin Anderson and David Krathwohl (Figure 8),31 it is clear that the theoretical parts of the workshop emphasized remembering and understanding and the practical parts focused on applying and creating.
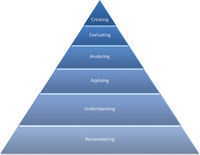
Figure 8. Taxonomy of learning objectives, according to Bloom (1956) and Anderson, Krathwohl, and Bloom (2001).
Analyzing the cognitive domain, on which learning goals 1-6 stressed, it becomes obvious (and had already been while planning the course) that we concentrated on the “higher level” categories: understanding, applying, analyzing, evaluating and creating.32 The “low level” category remembering, which Anderson, Krathwohl, and Bloom define as “retriev[ing] [i.e. recognizing and recalling] relevant knowledge from long-term memory,”33 was attempted but was not fully achievable. This was due to the time constraints of the workshop and especially the fact that in a comprehensive teaching approach as in summer schools (in comparison to a semester-long course with lectures every week) it is hardly possible to affect the long-term memory. In such a schedule there was simply insufficient time for students’ preparation, follow-ups and reflections in between sessions. As remembering also provides the basis for the “higher quality” objectives, this might also explain why the practical parts were so much slowed down in comparison to our plans and intention of accomplishing a completed project.
We believe that a “learning-by-project” approach as such is without doubt worth considering in teaching digital humanities. But one must be sensitive to the issues that might arise from the heterogeneity of the group and the fact that “higher” learning objectives, especially those in the category of creating, can only fully be achieved with a solid basis. A week-long course appears insufficient for a complex process that involves many different skills such as digital editing covering a wide range of learning objectives, as can be seen in the taxonomy by Bloom and by Anderson, Krathwohl, and Bloom.
Despite the digital edition of the corpus not being completed as intended, the aspiration and effort alone were beneficial. Students grasp a better sense of what digital editing as a holistic process involves, they learn at least how to conduct further self-directed studies and where to start their own projects and are definitely more motivated. We certainly would mutatis mutandis offer workshops and courses with the same aims again.
Footnotes
1 Peter Shillingsburg, From Gutenberg to Google: Electronic Representations of Literary Texts (Cambridge: Cambridge University Press, 2006), 94.
2 Elizabeth Burr, “Mission,” ESU Culture & Technology, University of Leipzig, October 15, 2010, http://www.culingtec.uni-leipzig.de/ESU/en/index_en.php?content=mission.
3 The authors wish to thank all participants of the workshop for their contribution and their willingness to participate in this experimental approach: Federico Caria, Claudia Di Fonzo, Małgorzata Eder, Natalia Ermolaev, Marc Andre Fortin, Jun Han, Marco Heiles, Stefanie Janßen, Julia Krasselt, and Annegret Richter.
4 “Introduction into the Creation of a Digital Edition,” ESU Culture & Technology, University of Leipzig, October 15, 2010, http://www.culingtec.uni-leipzig.de/ESU/en/index_en.php?content=../ESU_2010/en/workshops_2010.
5 According to Edward Vanhoutte’s typology, this meant creating a digital edition rather than digitizing an existing analog/print edition or generating the edition from a set of data; see Edward Vanhoutte, “Traditional Editorial Standards and the Digital Edition,” in Learned Love: Proceedings of the Emblem Project Utretch Conference on Dutch Love Emblems and the Internet (November 2006), ed. Els Stronks and Peter Boot (The Hague: DANS Symposium Publications, 2007), 157–74. Compare Thomas Stäcker, “Creating the Knowledge Site—Elektronische Editionen als Aufgabe einer Forschungsbibliothek,” in Digital Edition und Forschungsbibliothek, ed. Franz Fischer, Christiane Fritze, Patrick Sahle, and Malte Rebhein (special issue of Bibliothek und Wissenschaft, forthcoming), and Fotis Jannidis, “Digitale Editionen,” in Literatur im Medienwechsel, ed. Andrea Geier and Dietmar Till (Bielefeld: Aisthesis, 2008), 317–32.
6 For a more general introduction to teaching the scholarly editing of German texts, see Bodo Plachta, “Teaching Editing—Learning Editing,” Editio 13 (1999): 18-32.
7 Compare Shillingsburg, From Gutenberg to Google, 94.
8 Theorizing data modeling, developing models and managing the workflow around them can be regarded as the main reasoning behind digital humanities as a discipline.
9 See also Figure 1 in which we differentiate the outcome of the two modeling phases also technically: the XML schema for the representation of the source data and (mainly) the stylesheets (XSLT, CSS) for the presentation of the texts in the web (or any other medium).
10 For a definition of data representation and presentation in digital editing, see Patrick Sahle, “Zwischen Mediengebundenheit und Transmedialisierung. Anmerkungen zum Verhältnis von Edition und Medien,” Editio 24 (2010): 30.
11 In the German language, model theory distinguishes nicely between the two functions of models: an Abbild (of the reality)—the model of—on the one hand, and a Vorbild (the blueprint)—the model for—on the other; see Herbert Stachowiak, Allgemeine Modelltheorie (Wien: Springer, 1973).
12 Willard McCarty, “Modeling: A Study in Words and Meanings,” in A Companion to Digital Humanities, ed. Susan Schreibman, Ray Siemens, and John Unsworth (Malden: Blackwell, 2004), 255, emphasis original.
13 See Peter Langmann, “Einführung in die Datenmodellierung in den Geisteswissenschaften,” xlab, n.d., http://www.xlab.at/wordbar/definitionen/datenmodellierung.html.
14 On the entity-relationship model, see Peter Pin-Shan Chen, “The Entity-Relationship Model: Toward a Unified View of Data,” ACM Transactions on Database Systems 1, no. 1 (1976): 9–36.
15 For a more elaborate definition of transcription and text encoding in the context of the creation of electronic texts, see Allen H. Renear, “Text Encoding,” in A Companion to Digital Humanities, ed., Susan Schreibman, Ray Siemens, and John Unsworth, 218–39.
16 TEI Consortium, TEI P5: Guidelines for Electronic Text Encoding and Interchange, version 1.9.1, March 5, 2011, http://www.tei-c.org/release/doc/tei-p5-doc/en/html/.
17 McCarty, “Modeling,” 257.
18 This exchange of letters took place during the time when Salvarsan was officially marketed by Hoechst and introduced in 1910; see Amanda Yarnell, “Salvarsan,” Chemical & Engineering News 83, no. 25 (2005): 16. It also covers the time of the introduction of Neosalvarsan by Ehrlich in 1912, which he mentions in letters 18 (dated May 20, 1912) and 20 (dated November 7, 1913).
19 Diana Laurillard, Rethinking University Teaching, 2nd edn (New York: Routledge, 2002), 92.
20 Laurillard, Rethinking University Teaching, 62ff.
21 Laurillard, Rethinking University Teaching, 78.
22 Compare Donald Clark, “Learning Strategies,” Big Dog & Little Dog’s Performance Juxtaposition, July 5, 2010, http://www.nwlink.com/~donclark/hrd/strategy.html.
23 Laurillard, Rethinking University Teaching, 81ff.
24 See also Alexander Czmiel, “Editio ex machina: Digital Scholarly Editions out of the Box,” (paper presented at Digital Humanities 2008, University of Oulu, Oulu, Finland, June 25–28, 2008). The authors would like to thank Alexander Czmiel for his invaluable support in preparing and running the workshop.
25 We would like to thank the Digitization Centre of the Universitätsbibliothek Würzburg for doing this.
26 A major drawback from our original intention to let each participant work on two letters, i.e. to accomplish twenty letters overall.
27 Browsing by sender and recipient was possible only in theory, as all the letters had the same sender and recipient.
28 There were also a couple of minor issues addressed respectively by suggestions made by the students, which do not reflect on our approach as such. Suggestions that might be of general interest for teaching at summer schools encompass: providing a glossary of terms, handouts of slides and additional material (provided by us only on Moodle), charts and illustrations as references (e.g. of the process as a whole or the infrastructure).
29 Compare the results of a recent study of TEI-based manuscript encoding showing that it takes an average of 1.5 years from the first encounter of TEI until the first application in a project; see Marjorie Burghart and Malte Rehbein, “The Present and Future of the TEI Community for Manuscript Encoding,” Journal of the Text Encoding Initiative 2 (2012), http://jtei.revues.org/372.
30 As an alternative, the instructors could have prepared a best practice solution for each phase of the workflow and use these as input for the next phase instead of using what the group agreed upon.
31 Benjamin S. Bloom, Taxonomy of Educational Objectives, Handbook I: The Cognitive Domain (New York: David McKay, 1956), and Lorin W. Anderson, David R. Krathwohl, and Benjamin S. Bloom, A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives (New York: Longman, 2001).
32 For a definition of these categories, see Anderson, Krathwohl, and Bloom, A Taxonomy for Learning, Teaching, and Assessing, 67-68.
33 Anderson, Krathwohl, and Bloom, A Taxonomy for Learning, Teaching, and Assessing, 67.